Wikidata and the apt-get of things

In my peregrinations on P2P resources management systems, I regularly come back to the idea of an apt-get -like architecture. Now comes Wikidata, and it gives us a great opportunity to structure it!
[9/03/15 note]: I'm currenty prototyping in this direction at Inventaire.io. That's just a start, there is still a lot to be done to reach something like what is discribed in the present article and I won't go there alone: jump in already!
2 - Inventory Sources
3 - A clue on the naming system: wikidata + item patch
Post-Scriptum: Why being stubborn?
1 - What is apt-get? (and why it ROCKS!)
apt-get is Debian's packages manager, that is the piece of software that allows one to install any available software with a snap of the command-lines: entering the command apt-get install firefox will check the sources you registered to. If your sources can map your request to a piece of software, here firefox, it will download and install the appropriate software and its dependencies.
In the end, your sources are just a list of domains you trust to provide you with software in exchange of a valid request in debian's namespace.
# a sample of sources.list for debian
deb http://http.debian.net/debian wheezy main
Having the above line in you sources.list means you trust debian.net enough to provide you with software packages. By default, this sources are the one set by the distribution you installed (Debian, Ubuntu, Mint... make your choice!). The most astonishing thing about this when you come from proprietary operating systems is the ease with which this architecture allows you to update all your softwares at once:
{kind=link}
# make a request to your sources
# to check if anything as changed
apt-get update
# download the packages needed to apply the changes
apt-get upgrade
NB: If you are afraid of the commands, don't be, there are nice graphical user interfaces with shiny rounded angles, but UI/UX isn't in this article's scope.
But if the sources you registered to doesn't know the piece of software you're looking for or doesn't provide the version you want, you can just add new trusted domains following this standard to your source list. This will start to fetch information from this new source, extending the list of softwares known by your system. The best thing in this: you are not liable to a unique or even a few software providers, it's decentralized!
Political translation: decentralized = it's less difficult to take control
2 - Inventory sources
What about doing the same kind of architecture for things/resources - from the things you eat to the books you read - instead of softwares?
Today, when you want to buy a book or a new computer, you probably go to one of the few oligarchic resources management platforms: Amazon, Ebay, Carrefour, Walmart? Their online and offline funnels drives massive streams of customers and, as such, have a predominant control over their attention and buying behaviors (see episodes one and two).
But what if we could build resources information platforms in an apt-get way? What if my next search for a shovel wasn't on the website of a given gardening business oligarch but rather on a software/website using the information from the sources I registered to?
My sources.list could look something like:
https://my-neighborhood.org/businesses-inventories
https://my-city.org/peers-inventories
https://my-city.org/peers-inventories
https://my-city.org/businesses-inventories
https://my-favorite-brand.com/inventory
https://my-favorite-artisan.com/inventory
Nothing revolutionary in this: just as we have RSS source links such as http://my-blog.fr/rss for blog posts, we could have public links to fetch public resources and links with a privacy mechanism for private resources. And justs as there is hundreds of RSS feed aggregators to match the different needs, we could have a blooming of clients to aggregate those feeds. Mine would allow information crossing with third party sources such as
https://greenpeace.org/rankings-elements
https://corporateeurope.org/rankings-elements
but you do what you want: that's what Free-as-in-Free-speech-softwares are for! It could be hosted or not, on your personal cloud or hosted at the NSA, do as you please!
The point is first to get our information on resources out of businesses' control!
3 - A clue on the naming system: wikidata + a mapping to non-encyclopedic items
The problem we would encounter then is the one of the naming system in such a decentralized system: decentralization is a nice and brave aim but it's hard and there is no free lunch {fr}.
Meanwhile, there's a centralized naming system we can use today to start experimenting: Wikidata!
Do you know how to say Shovel / Schaufel / Pelle / Pala / シャベル / بیل in a worldwide non-ambiguous way? Wikidata knows: Q7220961!
Here is what I dream of:
inventory update
inventory fetch Q7220961
This query would provide a list of all the shovels that your trusted sources have knowledge of: the shovel the local retailer sells, the same one that your neigbor propose to buy as second-hand, the one your coworker declared wanting to give away etc. Depending of the client software you use, you might even be reminded of a shovel you bought a few years ago! This identifier might look ugly but user interfaces could easily do the translation to the local labels through the wikidata api.
Of course, various things have to be standardized around this basic naming system: relations and actions for instance. I don't know if the work done at Schema.org can help on that. I would really like to take advantage of all the work on the Linked Open Data, use JSON-LD and stuffs, but I don't see very precisely how it integrates yet: I just know it has all the reasons to connect eventually.
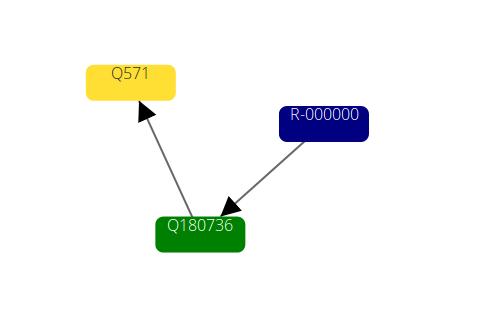
the object {id: R-000000, isbn: "2211215351", ean: "978-2211225350"} P31(is an instance of) => Q180736 (Les Misérables - V. Hugo) P31(is an instance of)=> Q571 (book)
This wikidata-based naming system would also benefit from being extended by a mapping with resources identifiers such as ISBN (books unique identifiers), GTIN (bar codes) etc.: that's what I'm working on and want to progress on in the coming months, and your help is welcome! This could hugely benefit from an acceleration of the OKFN Product-Open-Data project. By the way, Rufus Pollock's "CKAN: apt-get for the Debian of Data" talk was certainly an influence for the approach presented in this article, and CKAN could be an inspiration (if not an advantageously forkable project), but I didn't dig into it enough to see how.
Post-Scriptum: Why being stubborn?
just a memo on why I won't stop before it happens: there is no way I get scammed again buying hair clippers with glued/soldered batteries, dying after only 2 years. That's an information problem and not the kind businesses spontaneously highlight: we need to get structured information on resources out of marketers hand, and thus out of vendors platforms. {insert dramatic music sample here}

Any feedback welcome!
 This work is published under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
This work is published under a Creative Commons Attribution-ShareAlike 3.0 Unported License.Quoted text isn't affected by this license.